

特色论坛
CSIG优博论坛
论坛简介
论坛由中国图象图形学学会优博俱乐部组织承办,旨在为学会优秀博士论文奖获得者及导师提供学术交流与研讨的平台,促进学者之间的交流与合作。本次论坛计划邀请2024年度博士学位论文激励计划获得者及导师参加,活动形式将包含学术报告、优博Spotlight汇报和导师点评等环节。其中,学术报告讲者以优博导师为主,所讲内容为其前沿技术和最新成果;Spotlight汇报环节将邀请2024年度新入选优博进行汇报交流,并由导师专家进行点评指导。
论坛日程
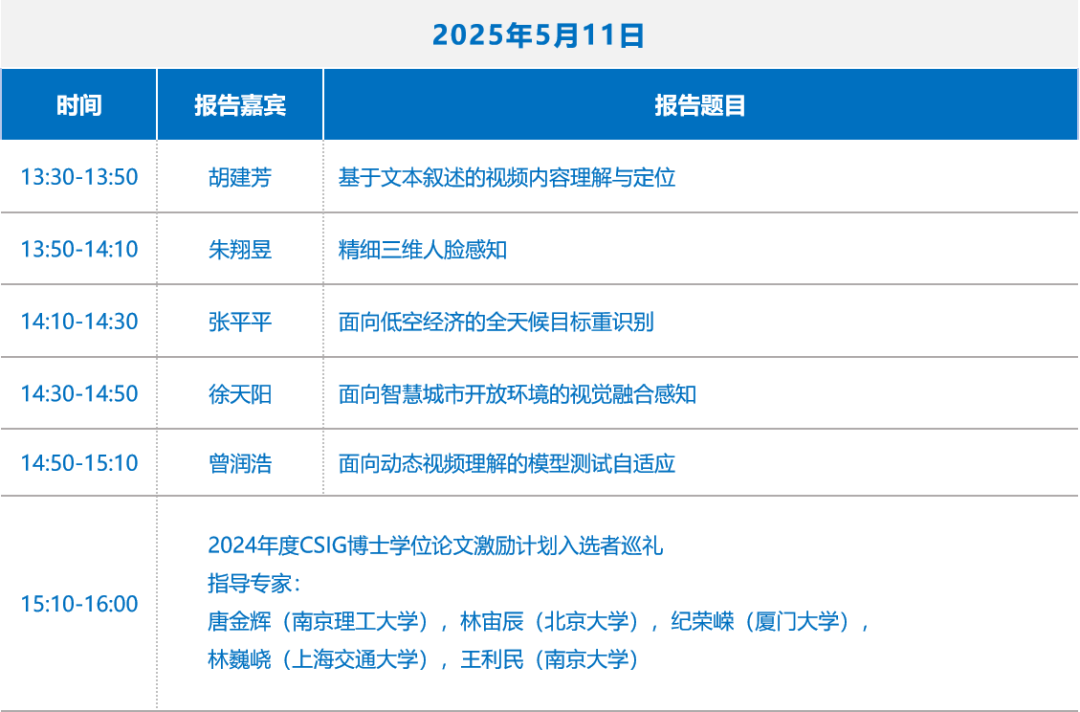
论坛时间:CSIG优博论坛
论坛名称:2025年5月11日13:30-16:00
主持人:张鼎文,马超,彭春蕾
论坛主席
 张鼎文西北工业大学 教授个人简介: 张鼎文,西北工业大学自动化学院教授、博导,国家优秀青年科学基金获得者、科睿唯安“全球高被引科学家”,曾赴美国卡耐基梅隆大学进行长期访问研究,致力于建立面向开放环境下、具备动态学习能力的新一代计算机视觉学习框架。迄今为业,作为第一作者/通讯,作者在领域内国际重要期刊及会议发表学术论文60余篇,其中包含T-PAMI, IJCV, IEEE SPM, T-IP, CVPR, ICCV, Science China: Information Science等,入选AI华人青年学者榜单,获吴文俊人工智能优秀青年奖、IEEE TCSVT最佳论文奖、中国图象图形学学会优秀博士论文奖等奖励。担任中国图象图形学学会青年工作委员会副秘书长,国际会议CVPR, ICCV等领域主席,国际期刊IEEE TMM与TCSVT编委等。
张鼎文西北工业大学 教授个人简介: 张鼎文,西北工业大学自动化学院教授、博导,国家优秀青年科学基金获得者、科睿唯安“全球高被引科学家”,曾赴美国卡耐基梅隆大学进行长期访问研究,致力于建立面向开放环境下、具备动态学习能力的新一代计算机视觉学习框架。迄今为业,作为第一作者/通讯,作者在领域内国际重要期刊及会议发表学术论文60余篇,其中包含T-PAMI, IJCV, IEEE SPM, T-IP, CVPR, ICCV, Science China: Information Science等,入选AI华人青年学者榜单,获吴文俊人工智能优秀青年奖、IEEE TCSVT最佳论文奖、中国图象图形学学会优秀博士论文奖等奖励。担任中国图象图形学学会青年工作委员会副秘书长,国际会议CVPR, ICCV等领域主席,国际期刊IEEE TMM与TCSVT编委等。 马超上海交通大学 教授个人简介: 马超,上海交通大学人工智能研究院教授,博士生导师。国家优青、上海市浦江人才、中国图象图形学学会优博。上海交通大学与加州大学默塞德分校联合培养博士。澳大利亚机器人视觉研究中心(阿德莱德大学)博士后研究员。主要研究计算机视觉问题。谷歌学术引用1万2千余次,连续入选爱思唯尔中国高被引学者(2020-2023)。任中国图象图形学学会优博俱乐部主席、青年工作委员会副秘书长。担任CVPR 2024/2025、ICLR 2025、ICCV 2025领域主席,IEEE Trans. on Multimedia (TMM)、Journal of Artificial Intelligence Research (JAIR)、Image and Vision Computing (IVC)编委。获中国图象图形学学会青年科学家奖、MMM 2024唯一最佳论文奖、华为技术合作领域优秀技术成果奖。
马超上海交通大学 教授个人简介: 马超,上海交通大学人工智能研究院教授,博士生导师。国家优青、上海市浦江人才、中国图象图形学学会优博。上海交通大学与加州大学默塞德分校联合培养博士。澳大利亚机器人视觉研究中心(阿德莱德大学)博士后研究员。主要研究计算机视觉问题。谷歌学术引用1万2千余次,连续入选爱思唯尔中国高被引学者(2020-2023)。任中国图象图形学学会优博俱乐部主席、青年工作委员会副秘书长。担任CVPR 2024/2025、ICLR 2025、ICCV 2025领域主席,IEEE Trans. on Multimedia (TMM)、Journal of Artificial Intelligence Research (JAIR)、Image and Vision Computing (IVC)编委。获中国图象图形学学会青年科学家奖、MMM 2024唯一最佳论文奖、华为技术合作领域优秀技术成果奖。
论坛讲者信息
>胡建芳中山大学 副教授报告题目: 基于文本叙述的视频内容理解与定位报告摘要: 随着多模态学习研究的快速发展,基于文本叙述的跨模态视频内容理解和定位成为计算机视觉与自然语言处理领域的重要研究方向。本报告将围绕实现不同语义粒度的视频-文本跨模态对齐学习展开,重点介绍研究团队在视频-文本内容定位、视频问答、视频-文本分割和跨模态视频生成方面的研究进展,并对视频-文本内容理解与定位研究领域进行总结和展望。个人简介: 胡建芳,中山大学副教授,博士生导师。主要从事多模态视频表征学习理论及应用研究,在国际权威期刊/会议发表论文60余篇。主持国家自然科学基金面上项目(2020和2025),广东省杰出青年基金(2022)项目,获中国图象图形学学会优秀博士学位论文奖,广东省自然科学奖二等奖,多次带领团队参加视频分析领域国际学术竞赛获一等奖。成果成功应用于安防监控、新冠肺炎防疫、中学实验操作智能打分、工业缺陷检测等重要工程和全国海关信息中心广东分中心、第九届亚洲冬季运动会、新疆喀什地区第一人民医院、腾讯与中山大学附属第三医院等重要企事业单位。- 朱翔昱中国科学院自动化研究所 副研究员报告题目: 精细三维人脸感知报告摘要: 人脸作为个体身份和情感特征的主要载体,在日常信息传递和情感表达中起着非常重要的作用,利用三维技术建模人脸的结构和行为,是人脸分析领域中的重要课题。特别在数字人、视频生成、以及VR/AR等技术的推动下,对精确人脸感知的需求不断攀升。重建更精细的人脸结构、更生动的人脸行为,以及更准确的人脸位姿成为研究焦点。报告将结合课题组研究,从人脸结构、表情和位姿三个方面的精细重建为大家介绍三维人脸感知的最新进展。个人简介: 朱翔昱,中国科学院自动化研究所副研究员,从事生物特征识别、数字人、人工智能基础理论的研究与应用。国际模式识别协会(IAPR)生物特征青年学者奖(YBIA)获得者(两年一次,每次从全球范围内评选40岁以下学者一名),获2024中国图象图形学学会自然科学二等奖(第一完成人)。发表论文100余篇,Google Scholar总引用次数为10000余次,获得三次国际竞赛冠军以及四项最佳论文及提名奖。授权国家发明专利16项。入选IEEE Senior Member,百度学术全球华人AI青年学者榜单(全球25人),受到腾讯犀牛鸟基金支持。任国际期刊TIFS、PR编委。提出的人脸三维建模方法在国际上产生了较广泛的影响力,相关成果被PyTorch官方Twitter报道,开源代码在Github上收获8000余星。
 张平平大连理工大学 副教授报告题目: 面向低空经济的全天候目标重识别报告摘要: 低空经济是空天技术与数字经济深度融合的战略性新兴产业集群,正成为培育新质生产力的重要增长极。作为低空经济领域的数字底座之一,全天候目标重识别具有广泛的应用场景,是智慧安防、智慧交通、智慧农业等重要应用的支撑性技术,然而其在真实应用场景中面临诸多挑战。报告将从数据模态和模型架构两个方面出发,介绍大连理工大学IIAU团队在全天候目标重识别方面所开展的一系列研究工作,以及相关技术在极端复杂环境下的应用实践。个人简介: 张平平,大连理工大学未来技术学院/人工智能学院副教授,研究方向为计算机视觉与深度学习。在相关领域的国际顶级会议和期刊(如CVPR/ICCV/AAAI/TPAMI/TIP等)上发表论文60余篇,谷歌学术引用6000余次。主持或参与国家重点研发、国家自然科学基金、省部级基金、开放课题等多项科研项目。目前为CSIG多媒体/类脑视觉专委会、CCF多媒体/计算机视觉专委会委员,担任多个国际顶级学术期刊和会议审稿人或领域主席,国内盛会VALSE第6-8届执行领域主席。曾以第一完成人身份获得辽宁省自然科学二等奖、中国图象图形学学会优秀博士论文奖、辽宁省优秀博士论文奖、大连市高端人才等。
张平平大连理工大学 副教授报告题目: 面向低空经济的全天候目标重识别报告摘要: 低空经济是空天技术与数字经济深度融合的战略性新兴产业集群,正成为培育新质生产力的重要增长极。作为低空经济领域的数字底座之一,全天候目标重识别具有广泛的应用场景,是智慧安防、智慧交通、智慧农业等重要应用的支撑性技术,然而其在真实应用场景中面临诸多挑战。报告将从数据模态和模型架构两个方面出发,介绍大连理工大学IIAU团队在全天候目标重识别方面所开展的一系列研究工作,以及相关技术在极端复杂环境下的应用实践。个人简介: 张平平,大连理工大学未来技术学院/人工智能学院副教授,研究方向为计算机视觉与深度学习。在相关领域的国际顶级会议和期刊(如CVPR/ICCV/AAAI/TPAMI/TIP等)上发表论文60余篇,谷歌学术引用6000余次。主持或参与国家重点研发、国家自然科学基金、省部级基金、开放课题等多项科研项目。目前为CSIG多媒体/类脑视觉专委会、CCF多媒体/计算机视觉专委会委员,担任多个国际顶级学术期刊和会议审稿人或领域主席,国内盛会VALSE第6-8届执行领域主席。曾以第一完成人身份获得辽宁省自然科学二等奖、中国图象图形学学会优秀博士论文奖、辽宁省优秀博士论文奖、大连市高端人才等。 徐天阳江南大学 副教授报告题目: 面向智慧城市开放环境的视觉融合感知报告摘要: 开放环境下视觉感知是构建智慧城市若干智能视觉系统的重要研究基础,其受场景多样性和模态差异等因素影响。为了应对上述挑战,针对开放场景多分布的视觉数据进行有效感知建模尤为重要。本报告介绍多任务统一图像融合框架设计、退化场景下视觉目标跟踪模型、以及人体行为识别网络构建等方面的研究进展。个人简介: 徐天阳,江南大学副教授。博士毕业于江南大学模式识别与智能系统专业,后于Centre for Vision, Speech and Signal Processing (CVSSP)担任Research Fellow,现任江南大学人工智能与计算机学院副教授。研究方向为视频理解,发表IEEE TPAMI、IJCV、IEEE TIP、CVPR、ICCV、ECCV等CCF-A/IEEE汇刊40余篇,其中IEEE TPAMI/IJCV 8篇,谷歌学术引用5000余次,获中国图象图形学学会优秀博士学位论文奖,获CVPR/ICCV/ECCV等学术会议举办的视觉目标跟踪和行为识别学术竞赛(VOT、MMVRAC、Anti-UAV、AI City Challenge、Perception Test Challenge)冠亚军10余项,入选斯坦福大学全球前2%顶尖科学家年度榜单。服务领域内期刊和会议的SAC/AC/Reviewer,组织CVPR/ICPR/PRCV/VALSE等大会、竞赛、论坛和讲习班。
徐天阳江南大学 副教授报告题目: 面向智慧城市开放环境的视觉融合感知报告摘要: 开放环境下视觉感知是构建智慧城市若干智能视觉系统的重要研究基础,其受场景多样性和模态差异等因素影响。为了应对上述挑战,针对开放场景多分布的视觉数据进行有效感知建模尤为重要。本报告介绍多任务统一图像融合框架设计、退化场景下视觉目标跟踪模型、以及人体行为识别网络构建等方面的研究进展。个人简介: 徐天阳,江南大学副教授。博士毕业于江南大学模式识别与智能系统专业,后于Centre for Vision, Speech and Signal Processing (CVSSP)担任Research Fellow,现任江南大学人工智能与计算机学院副教授。研究方向为视频理解,发表IEEE TPAMI、IJCV、IEEE TIP、CVPR、ICCV、ECCV等CCF-A/IEEE汇刊40余篇,其中IEEE TPAMI/IJCV 8篇,谷歌学术引用5000余次,获中国图象图形学学会优秀博士学位论文奖,获CVPR/ICCV/ECCV等学术会议举办的视觉目标跟踪和行为识别学术竞赛(VOT、MMVRAC、Anti-UAV、AI City Challenge、Perception Test Challenge)冠亚军10余项,入选斯坦福大学全球前2%顶尖科学家年度榜单。服务领域内期刊和会议的SAC/AC/Reviewer,组织CVPR/ICPR/PRCV/VALSE等大会、竞赛、论坛和讲习班。 曾润浩深圳北理莫斯科大学 长聘副教授报告题目: 面向动态视频理解的模型测试自适应报告摘要: 测试时自适应(Test-Time Adaptation, TTA)是提升视频模型在未知场景下鲁棒性与泛化能力的重要途径。然而,在动态视频理解中,TTA仍面临以下三大挑战:1)运动建模不足:视频特有的时空关联性被忽视;2)模态利用单一:音频等伴随信息未得到充分挖掘;3)优化效率低下:传统方法收敛速度较慢、适应过程耗时较长。为此,我们提出了应对方案:1)动态感知增强:设计基于快慢采样的特征对齐机制,通过跨速率的交互建模捕捉运动线索,提升模型对动态场景的自适应能力;2)跨模态协同进化:构建音频辅助的视频TTA框架,利用预训练音频模型与大语言模型进行语义映射,实现音视频联合优化;3)高效优化引擎:提出基于学习的测试时元梯度优化器,通过历史信息的压缩、记忆与重用在保证准确度的同时降低计算开销,实现快速、稳定的在线自适应。个人简介: 曾润浩,博士,深圳北理莫斯科大学长聘副教授,博士生导师。广东省重大人才工程青年拔尖人才,深圳市科技创新人才,深圳市鹏城孔雀人才,广东潮博智库专家。研究领域为计算机视觉、多模态数据分析,核心方向包括视频动作识别、情绪识别等,在IEEE TPAMI、IEEE TIP、CVPR等国际顶级期刊和会议发表论文20余篇,谷歌学术总引1800余次,单篇最高引600余次。所提出的视频时序动作分析方法在THUMOS14权威基准连续14个月排名全球第一,成果收录于科普教材《机器视觉》,获评第31届书博会少儿阅读节百种优秀图书并输出两种外语版权。近三年主持国家自然科学基金项目、广东省教育厅重点领域项目等纵向科研项目7项。获中国图象图形学学会优博提名奖,IEEE杰出组织奖,成果入选计算机视觉国际顶级会议CVPR 2024最佳论文候选。受邀担任NeurIPS、CVPR等人工智能领域顶级会议和TPAMI、TIP等权威期刊的程序委员会委员和审稿人。担任国际会议2024 IEEE SmartIoT本地主席、2023 CSIG青年科学家会议论坛主席,广东图象图形学会计算机视觉专委会委员。
曾润浩深圳北理莫斯科大学 长聘副教授报告题目: 面向动态视频理解的模型测试自适应报告摘要: 测试时自适应(Test-Time Adaptation, TTA)是提升视频模型在未知场景下鲁棒性与泛化能力的重要途径。然而,在动态视频理解中,TTA仍面临以下三大挑战:1)运动建模不足:视频特有的时空关联性被忽视;2)模态利用单一:音频等伴随信息未得到充分挖掘;3)优化效率低下:传统方法收敛速度较慢、适应过程耗时较长。为此,我们提出了应对方案:1)动态感知增强:设计基于快慢采样的特征对齐机制,通过跨速率的交互建模捕捉运动线索,提升模型对动态场景的自适应能力;2)跨模态协同进化:构建音频辅助的视频TTA框架,利用预训练音频模型与大语言模型进行语义映射,实现音视频联合优化;3)高效优化引擎:提出基于学习的测试时元梯度优化器,通过历史信息的压缩、记忆与重用在保证准确度的同时降低计算开销,实现快速、稳定的在线自适应。个人简介: 曾润浩,博士,深圳北理莫斯科大学长聘副教授,博士生导师。广东省重大人才工程青年拔尖人才,深圳市科技创新人才,深圳市鹏城孔雀人才,广东潮博智库专家。研究领域为计算机视觉、多模态数据分析,核心方向包括视频动作识别、情绪识别等,在IEEE TPAMI、IEEE TIP、CVPR等国际顶级期刊和会议发表论文20余篇,谷歌学术总引1800余次,单篇最高引600余次。所提出的视频时序动作分析方法在THUMOS14权威基准连续14个月排名全球第一,成果收录于科普教材《机器视觉》,获评第31届书博会少儿阅读节百种优秀图书并输出两种外语版权。近三年主持国家自然科学基金项目、广东省教育厅重点领域项目等纵向科研项目7项。获中国图象图形学学会优博提名奖,IEEE杰出组织奖,成果入选计算机视觉国际顶级会议CVPR 2024最佳论文候选。受邀担任NeurIPS、CVPR等人工智能领域顶级会议和TPAMI、TIP等权威期刊的程序委员会委员和审稿人。担任国际会议2024 IEEE SmartIoT本地主席、2023 CSIG青年科学家会议论坛主席,广东图象图形学会计算机视觉专委会委员。


指导专家
 唐金辉南京理工大学 教授个人简介: 唐金辉,南京理工大学计算机科学与工程学院二级教授、院长,国家杰出青年基金获得者、国家“万人计划”科技创新领军人才、IAPR Fellow,主要从事多媒体分析与检索、计算机视觉和模式识别等方面的研究,在IEEE/ACM汇刊和CCF A类会议上发表学术论文200余篇,谷歌学术引用超过23000次,H-index为78,主持国家自然科学基金重点项目2项、科技创新2030新一代人工智能重大专项课题、973计划青年科学家专题项目等,获国家自然科学二等奖1项、省部级科学技术一等奖4项、教育部自然科学奖二等奖2项,获ACM MM 2007和ACM MM Asia 2020的最佳论文奖,以及ACM MM 2015的最佳论文奖提名,担任或曾任IEEE TKDE、TMM、TNNLS和TCSVT等权威国际期刊编委。
唐金辉南京理工大学 教授个人简介: 唐金辉,南京理工大学计算机科学与工程学院二级教授、院长,国家杰出青年基金获得者、国家“万人计划”科技创新领军人才、IAPR Fellow,主要从事多媒体分析与检索、计算机视觉和模式识别等方面的研究,在IEEE/ACM汇刊和CCF A类会议上发表学术论文200余篇,谷歌学术引用超过23000次,H-index为78,主持国家自然科学基金重点项目2项、科技创新2030新一代人工智能重大专项课题、973计划青年科学家专题项目等,获国家自然科学二等奖1项、省部级科学技术一等奖4项、教育部自然科学奖二等奖2项,获ACM MM 2007和ACM MM Asia 2020的最佳论文奖,以及ACM MM 2015的最佳论文奖提名,担任或曾任IEEE TKDE、TMM、TNNLS和TCSVT等权威国际期刊编委。 林宙辰CSIG理事
林宙辰CSIG理事
北京大学 教授个人简介: 林宙辰,北京大学智能学院副院长,博雅特聘教授,研究领域为机器学习和计算机视觉。他在人工智能核心期刊和会议上发表论文330余篇,出版中英文专著5本,谷歌引用数为38,000余次。他曾多次担任多个业内顶级会议的领域主席和资深领域主席。他曾获2024年度CAA、2023年度CAAI和2020年度CCF科学技术奖自然科学一等奖(均排名第一)。他是中国图象图形学学会(CSIG)机器视觉专委会前主任,中国自动化学会模式识别与机器智能专委会副主任,IAPR、IEEE、CSIG和AAIA的会士,国家杰青,科技部科技创新2030-“新一代人工智能”重大项目负责人。 纪荣嵘厦门大学 教授个人简介: 纪荣嵘,厦门大学南强特聘教授,科技处处长,人工智能研究院执行院长,教育部重点实验室主任。国家杰青、国家优青、中组部万人青拔、国务院特殊津贴获得者。长期从事人工智能领域前沿技术研究,近年来发表领域顶级期刊会议长文百余篇,谷歌学术引用近3万次。获2016年教育部技术发明一等奖、2018、2020、2023年省科技进步一等奖、2022年霍英东青年科学奖,国家人工智能国家标准工作组联合组长。
纪荣嵘厦门大学 教授个人简介: 纪荣嵘,厦门大学南强特聘教授,科技处处长,人工智能研究院执行院长,教育部重点实验室主任。国家杰青、国家优青、中组部万人青拔、国务院特殊津贴获得者。长期从事人工智能领域前沿技术研究,近年来发表领域顶级期刊会议长文百余篇,谷歌学术引用近3万次。获2016年教育部技术发明一等奖、2018、2020、2023年省科技进步一等奖、2022年霍英东青年科学奖,国家人工智能国家标准工作组联合组长。 林巍峣上海交通大学 教授个人简介: 林巍峣,上海交通大学特聘教授,主要研究方向为人工智能,视频分析,视觉表征编码等。在相关领域发表权威期刊和会议论文100余篇,获发明专利25项。获DanceTrack、GigaDetection等多项国际权威评测第一;多项技术被国际和国内权威视频编码标准采纳,并牵头制定视觉特征编码团体标准。获得中国高交会、工博会优秀产品奖,中国产学研合作创新奖。入选IEEE多媒体计算中期职业成就奖、IEEE ICME多媒体学术新星奖。任多个权威期刊编委、会议领域主席及权威标准化工作组组长。获国家杰出青年科学基金、国家自然科学基金联合重点等项目资助。
林巍峣上海交通大学 教授个人简介: 林巍峣,上海交通大学特聘教授,主要研究方向为人工智能,视频分析,视觉表征编码等。在相关领域发表权威期刊和会议论文100余篇,获发明专利25项。获DanceTrack、GigaDetection等多项国际权威评测第一;多项技术被国际和国内权威视频编码标准采纳,并牵头制定视觉特征编码团体标准。获得中国高交会、工博会优秀产品奖,中国产学研合作创新奖。入选IEEE多媒体计算中期职业成就奖、IEEE ICME多媒体学术新星奖。任多个权威期刊编委、会议领域主席及权威标准化工作组组长。获国家杰出青年科学基金、国家自然科学基金联合重点等项目资助。 王利民南京大学 教授个人简介: 王利民,南京大学教授,博士生导师,国家海外高层次青年人才计划入选者,科技创新2030-“新一代人工智能”重大项目青年科学家。主要研究领域为计算机视觉和深度学习,专注视频理解和动作识别,在IJCV、T-PAMI、CVPR、ICCV、NeurIPS等学术期刊和会议发表论文100余篇,论文引用3万余次。在视频分析领域做出了一系列有重要影响力的研究工作,例如:TDD视频深度特征、TSN视频网络架构,VideoMAE视频预训练方法,MixFormer目标跟踪器等。曾获得广东省技术发明一等奖,ACM MM 2023最佳论文提名奖、世界人工智能大会青年优秀论文奖。入选2022年度AI 2000人工智能全球最具影响力学者榜单,2022年度全球华人AI青年学者榜单,2021-2023年度爱思唯尔中国高被引学者榜单。担任CVPR/ICCV/NeurIPS等重要国际会议的领域主席和计算机视觉领域旗舰期刊IJCV的编委。
王利民南京大学 教授个人简介: 王利民,南京大学教授,博士生导师,国家海外高层次青年人才计划入选者,科技创新2030-“新一代人工智能”重大项目青年科学家。主要研究领域为计算机视觉和深度学习,专注视频理解和动作识别,在IJCV、T-PAMI、CVPR、ICCV、NeurIPS等学术期刊和会议发表论文100余篇,论文引用3万余次。在视频分析领域做出了一系列有重要影响力的研究工作,例如:TDD视频深度特征、TSN视频网络架构,VideoMAE视频预训练方法,MixFormer目标跟踪器等。曾获得广东省技术发明一等奖,ACM MM 2023最佳论文提名奖、世界人工智能大会青年优秀论文奖。入选2022年度AI 2000人工智能全球最具影响力学者榜单,2022年度全球华人AI青年学者榜单,2021-2023年度爱思唯尔中国高被引学者榜单。担任CVPR/ICCV/NeurIPS等重要国际会议的领域主席和计算机视觉领域旗舰期刊IJCV的编委。
论坛联系人
- 彭春蕾西安电子科技大学clpeng@xidian.edu.cn

