用科技创新让世界更高效——合合信息智能文档处理技术分享
合合信息智能文档处理技术的领先性获得国内外广泛认可。国际层面,公司近三年来先后在ICDAR、ICPR等人工智能国际竞赛中斩获15项冠军,学术成果在ICCV、CVPR、AAAI、ACL、ACM MM等顶会上发表。在国内,合合信息运用多项创新技术,显著提升复杂场景下文字识别与理解的性能和效果,“复杂场景文档图像识别与理解关键技术及应用”相关项目获中国图象图形学学会(CSIG)科技进步奖二等奖,CSIG科技成果鉴定会委员认为,该项目在复杂场景文档图像识别与理解技术方面取得了创造性的成果,并具有自主知识产权,整体技术达到国际先进水平“。

接下来,CSIG将对合合信息智能图像处理、文字检测与识别、文档结构化信息抽取等智能文档处理优势技术进行分享。
核心技术模块1|
智能图像处理:为文字识别“增质提效”筑基
智能图像处理是指利用AI技术,对复杂场景中的图像进行自动识别和要素分析。受拍摄设备、拍摄环境等多方因素的制约,文档原始图像往往存在亮度不均、模糊、背景杂乱、页面残缺、透视变形等多种问题。合合信息智能图像处理技术可帮助各应用领域简化下游文档处理任务,提升后续文字识别的效率与准确性。
1.1切边增强:
合合信息切边增强技术可以智能判断照片中主体文档的边缘进行切边,同时增强图像突出文字,可在杂乱的背景中,聚焦到核心的文档内容,大幅度提升文档图像的质量。
解决问题:
当采集的业务材料图像存在着多余背景、主体过小、角度倾斜等问题时,通过合合信息的切边增强技术,可自动裁切出图像主体区域,并增强图像质量,经过该项处理后再进入后续的文字识别、信息提取、材料审核等业务,提升文档处理速度与质量。
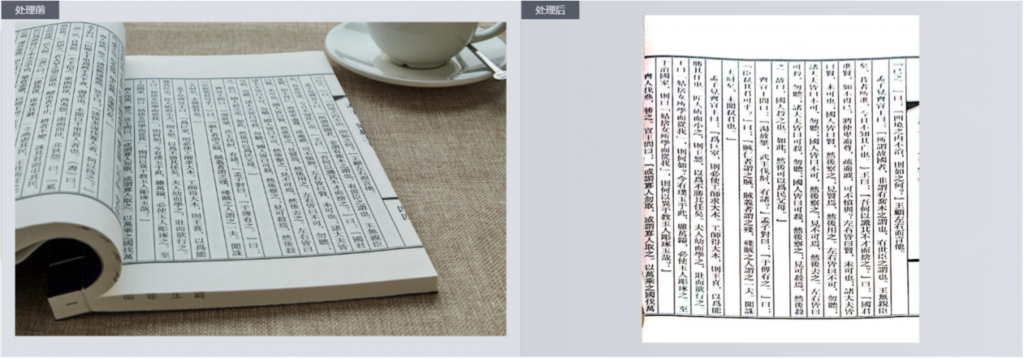
1.2弯曲矫正:
合合信息弯曲矫正技术创新性地采用基于位移场网络学习方法的系统构架,可对弯曲地文档进行曲面、透视矫正,同时智能定位文档边缘,切除多余背景。
解决问题:
手持镜头拍照得到的文档图像往往存在着复杂的几何形变,包括拍摄视角、纸张本身的折叠、褶皱、弯曲以及厚度等因素,都会造成拍摄图像存在畸变,极大地影响了视觉观感和后续内容识别工作的进行。

1.3去摩尔纹:
合合信息去摩尔纹技术采用多重神经网络技术,通过分析暗角、摩尔纹的形成原理,对图像中存在的干扰因素进行对应处理,可去除所有样式的摩尔纹,同时保证图像信息完整、颜色不失真。
解决问题:
使用相机拍摄电子屏幕,图像上会出现呈现条状、网状、波纹状等多种形态、颜色各异的摩尔纹(也称为屏幕纹)。如果不能进行及时去除,既影响图片观感,叠加在图像上的纹路也会破坏图片原有信息,对后续的内容提炼造成障碍。

核心技术模块2|
文字检测与识别:精准实现多场景、多语言的内容提取
文字检测与识别技术主要对多版式、多格式的文档图像段落、表格、图片等内容信息及其位置关系进行解析、理解,不仅需要产品具备检测多样式版面的能力,也要具备多语言的识别能力,方能服务于更广泛的群体。据权威机构检测,合合信息印刷体文档字符平均识别率为99.77%,支持全球超50种语言的文字识别与信息提取。
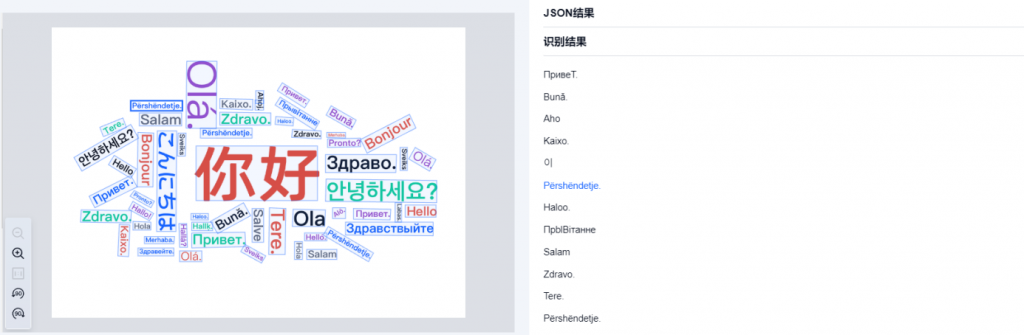
2.1文字检测与识别:
相较于传统的OCR技术,合合信息文字检测与识别技术具备更多认知与理解能力,可适应多语言、多版式、多样式的复杂场景,通用性强。
多语言、不规则版式下的识别图例如下:
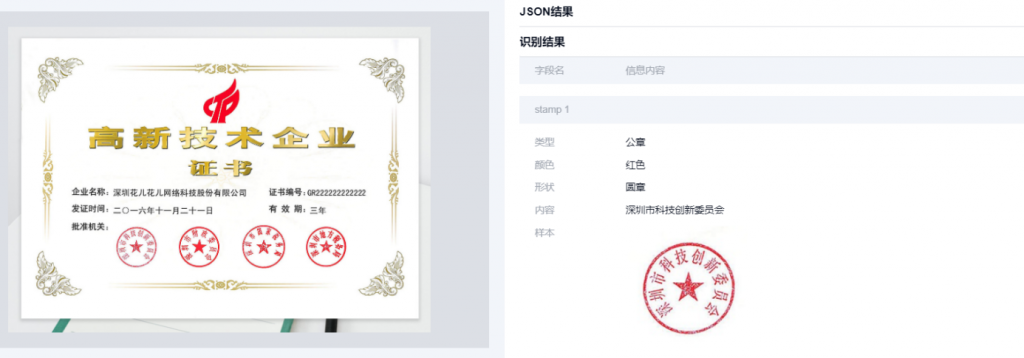
2.2印章检测与识别:
合合信息印章检测与识别技术支持检测并识别多行业合同文件和票据中的印章,结构化返回票据等样本上单个/多个印章上文字,支持红章/黑章,常规印章(圆章/方章等),可控制印章切图外扩留白范围。
解决问题:
印章种类规格多样,形状有方形、椭圆形、圆形之分,文字的方向、排版差异巨大,通常存在不同程度的遮挡、背景干扰、重叠,以及颜色深浅不一等状况。传统OCR技术方案在过度曝光、反光、抖动、光线弱等复杂情境下的处理能力有限,无法满足印章文件等非常规文本的识别需求,合合信息印章检测识别技术可解决这个问题。
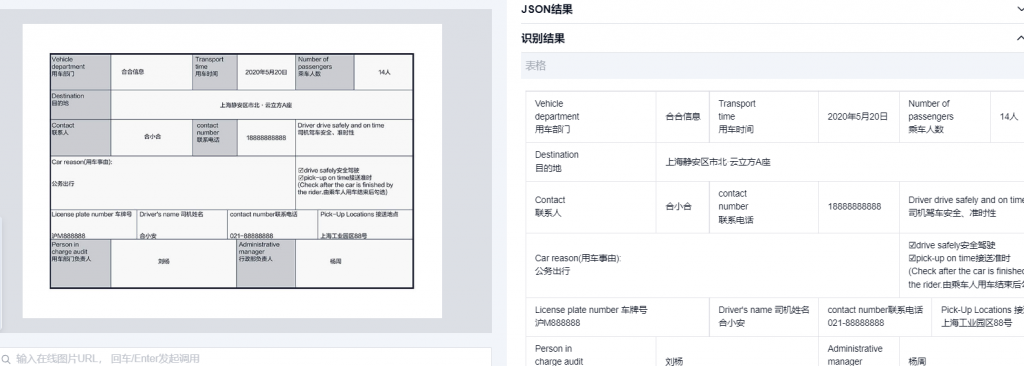
表格检测与识别:
合合信息表格检测与识别技术支持识别图片/PDF格式文档中的表格内容,包括有线表格、无线表格、合并单元格表格,同时支持单张图片内的多个表格内容识别,返回各表格的表头表尾内容、单元格文字内容及其行列位置信息。
解决问题:
基于分治思想,合合信息引入深度学习技术,将表格识别分为有线表识别和无线表识别两种方案。在财报相关表格识别测试中,合合信息有线表识别单元格结构准确率高于98%;无线表识别是表格识别中的难点,合合信息无线表识别在保证表格区域内容的完整性的同时,检测准确率较传统方法显著提升。
核心技术模块3|
文档结构化信息抽取:非结构化信息处理能力赋能开发与应用
文档结构化信息抽取指把图片等原始内容载体中包含的信息进行结构化处理,变成表格一样的结构化组织形式,以统一的形式集成在一起,方便后序的检索和比较。合合信息通过自然语言处理技术对文本内容进行抽取和深度挖掘,在合同、标书、榜单、网页等类型多样、非标准化的长文本信息提取中表现效果优异。该领域主要技术方向有关键信息抽取、智能理解、分析等,目前已被应用于合合信息TextIn智能文字识别训练平台及财报机器人、合同机器人中,助力行业开发应用。
关键信息抽取
针对长文本信息抽取需求,合合信息基于自然语言处理(NLP)技术,研发了通用NLP信息抽取引擎,可从不同类型、版式、篇幅的长文本中快速抽取出特定信息,有效提升业务效率,并提供多种部署方式。

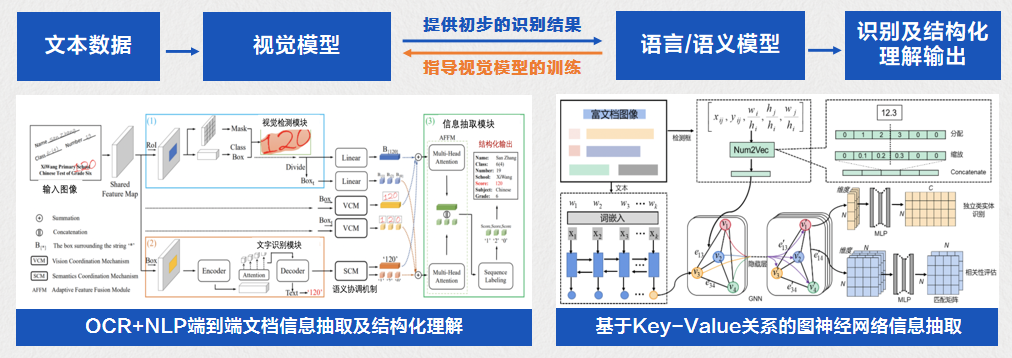
“数据+知识双驱动“图像理解
合合信息”数据+知识双驱动“图像理解技术创新性地提出了基于数据及知识双驱动、端到端地文本图像识别及结构化理解新方法,提升对图像文本内容的智能理解和信息抽取能力,在名片的关键信息理解、海外票据及货运单等非固定版式信息理解、合同等长文档的信息理解工作中应用广泛。
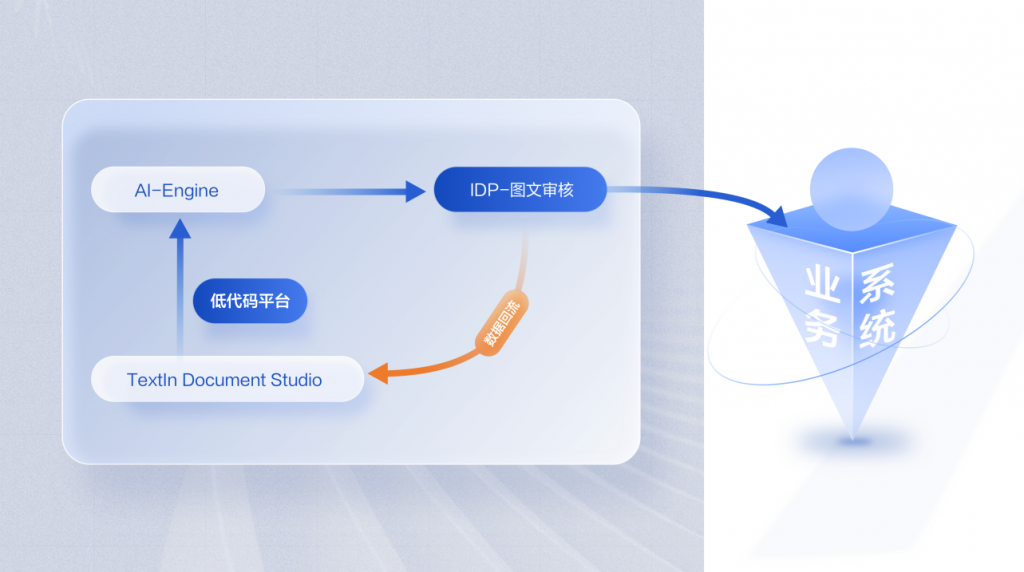
产品介绍:合合信息智能文档处理系统 ——10分钟完成模型开发
合合信息智能文档处理系统主要由智能图像处理、文档识别及版面分析、文档结构化信息抽取底层技术组成的基础算法层,面向企业应用者提供的文档识别标准模块,以及面向开发者的智能文字识别训练平台构成,提升智能文档企业应用及开发效率。
该系统支持超过200种卡证照票据识别api的调用,并内置了场景丰富的预训练模型,配备专项模型类型,以满足固定版式、半固定版式、不固定版式文档的识别与分类需求,可对单页/多页、任意版式文档,提取自定义的结构化信息。
低代码操作方式可助力企业开发者在满足识别精度的基础上,降低训练难度,快速产出满足业务需求的OCR模型。据悉,实测中应用人员最短可在10分钟内完成抽取模型开发全流程,可视化界面设计让没有算法基础的业务人员也可顺利使用。
此外,合合信息智能文档处理系统还具备数据回流功能,将实际业务中产生的标注信息数据回流进行训练,实现“在业务场景中越用越好用”的持续迭代效果,持续提升识别精度,真正做到了智能化和终身学习。